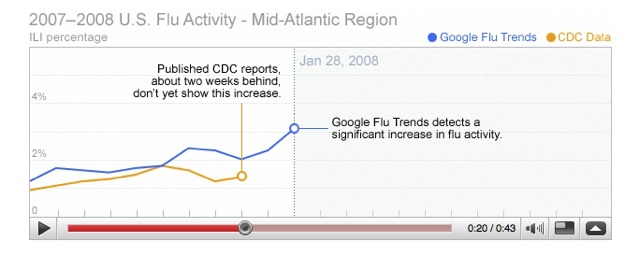
Following on from this post and today’s Observer column, I’ve had some feedback asking how one might go about using Google queries as forward indicators of economic developments. The answer is that I don’t know, but it probably hinges on finding the right search queries to map. Here are some experiments I’ve done.
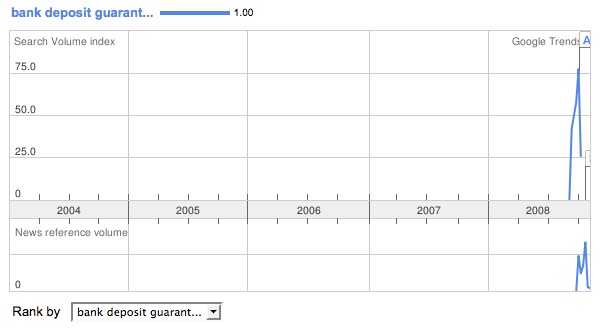
This suggests that people weren’t really concerned about bank deposit guarantees until August 2008. I don’t believe this, so perhaps this is the wrong search term to be tracking.
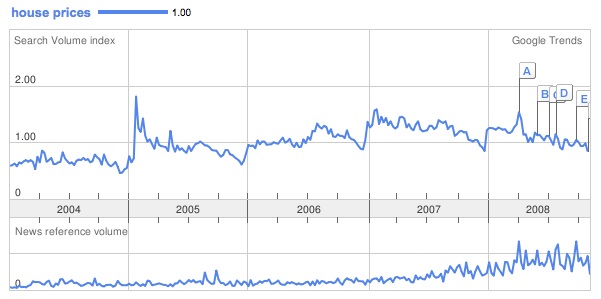
This suggests that the peak of interest in house prices occurred in 2005 and is now in gentle decline. This might indicate that this search term is a token for general curiosity (“wonder why our house is worth at the moment?”) rather than alarm. It’s interesting to compare this with the chart for ‘negative equity’ below.
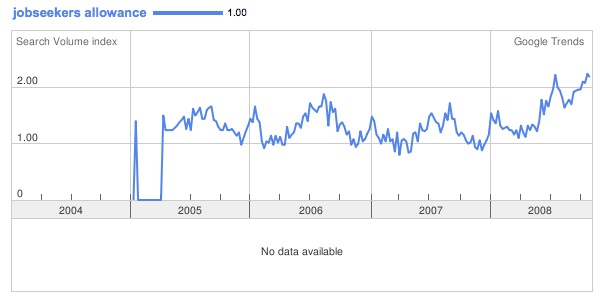
This has a regular annual cycle but is now clearly on the rise. Again, it’s not clear that it has much predictive power.
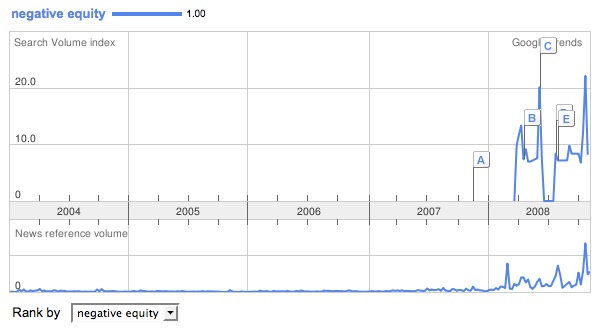
Speaks for itself, I think.
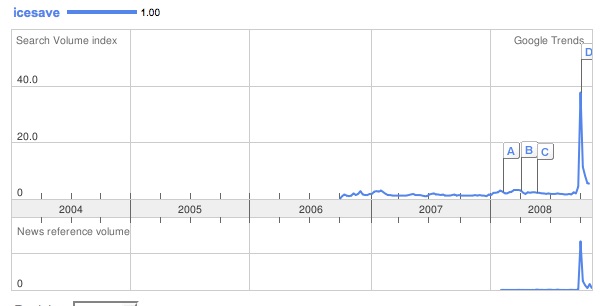
Ditto.
As I say, the trick would be to identify search terms which would give an indication of what people know or suspect about their organisational future.
There’s nothing terribly systematic about this — I was just trying to think of search terms that might reveals what people were thinking as they realise that they face an uncertain future.
Tony Hirst, who is the nearest thing to a wizard with Google data that I know, has some interesting things to say about the topic. He’s also knowledgeable about the limitations of the Google data.