As a critic of many of the ways that digital technology is currently being exploited by both corporations and governments, while also being a fervent believer in the positive affordances of the technology, I often find myself stuck in unproductive discussions in which I’m accused of being an incurable “pessimist”. I’m not: better descriptions of me are that I’m a recovering Utopian or a “worried optimist”.
Part of the problem is that the public discourse about this stuff tends to be Manichean: it lurches between evangelical enthusiasm and dystopian gloom. And eventually the discussion winds up with a consensus that “it all depends on how the technology is used” — which often leads to Melvin Kranzberg’s Six Laws of Technology — and particularly his First Law, which says that “Technology is neither good nor bad; nor is it neutral.” By which he meant that,
“technology’s interaction with the social ecology is such that technical developments frequently have environmental, social, and human consequences that go far beyond the immediate purposes of the technical devices and practices themselves, and the same technology can have quite different results when introduced into different contexts or under different circumstances.”
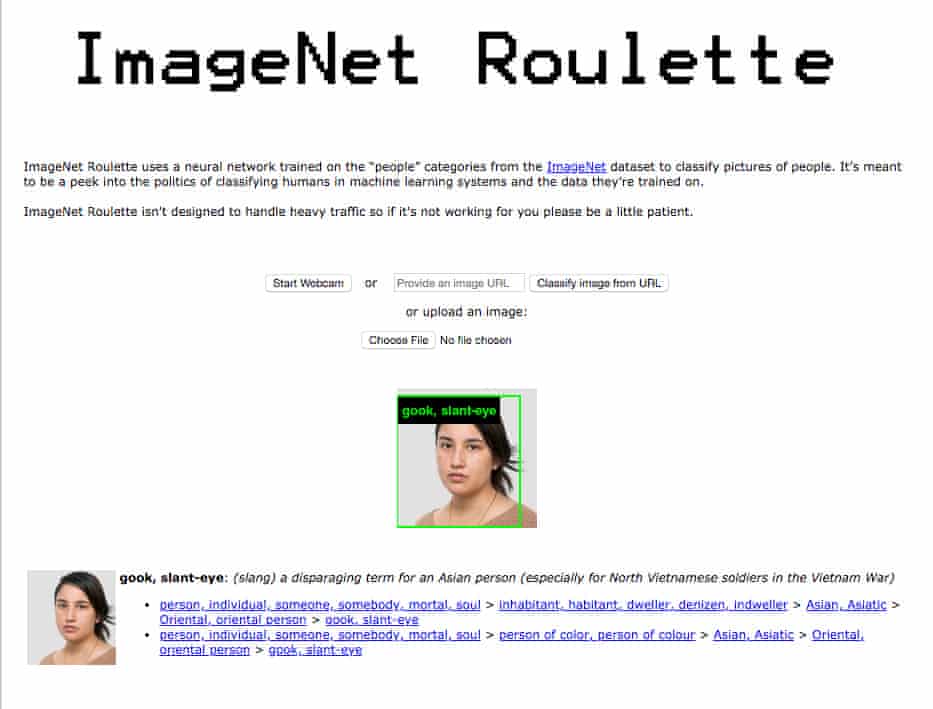
Many of the current discussions revolve around various manifestations of AI, which means machine learning plus Big Data. At the moment image recognition is the topic du jour. The enthusiastic refrain usually involves citing dramatic instances of the technology’s potential for social good. A paradigmatic example is the collaboration between Google’s DeepMind subsidiary and Moorfields Eye Hospital to use machine learning to greatly improve the speed of analysis of anonymized retinal scans and automatically flag ones which warrant specialist investigation. This is a good example of how to use the technology to improve the quality and speed of an important healthcare service. For tech evangelists it is an irrefutable argument for the beneficence of the technology.
On the other hand, critics will often point to facial recognition as a powerful example for the perniciousness of machine-learning technology. One researcher has even likened it to plutonium. Criticisms tend to focus on its well-known weaknesses (false positives, racial or gender bias, for example), its hasty and ill-considered use by police forces and proprietors of shopping malls, the lack of effective legal regulation, and on its use by authoritarian or totalitarian regimes, particularly China.
Yet it is likely that even facial recognition has socially beneficial applications. One dramatic illustration is a project by an Indian child labour activist, Bhuwan Ribhu, who works for the Indian NGO Bachpan Bachao Andolan. He launched a pilot program 15 months prior to match a police database containing photos of all of India’s missing children with another one comprising shots of all the minors living in the country’s child care institutions.
The results were remarkable. “We were able to match 10,561 missing children with those living in institutions,” he told CNN. “They are currently in the process of being reunited with their families.” Most of them were victims of trafficking, forced to work in the fields, in garment factories or in brothels, according to Ribhu.
This was made possible by facial recognition technology provided by New Delhi’s police. “There are over 300,000 missing children in India and over 100,000 living in institutions,” he explained. “We couldn’t possibly have matched them all manually.”
This is clearly a good thing. But does it provide an overwhelming argument for India’s plan to construct one of the world’s largest facial-recognition systems with a unitary database accessible to police forces in 29 states and seven union territories?
I don’t think so. If one takes Kranzberg’s First Law seriously, then each proposed use of a powerful technology like this has to face serious scrutiny. The more important question to ask is the old Latin one: Cui Bono?. Who benefits? And who benefits the most? And who loses? What possible unintended consequences could the deployment have? (Recognising that some will, by definition, be unforseeable.) What’s the business model(s) of the corporations proposing to deploy it? And so on.
At the moment, however, all we mostly have is unasked questions, glib assurances and rash deployments.