Michael Arrington wants to build a Web tablet Here’s his mock-up pic.
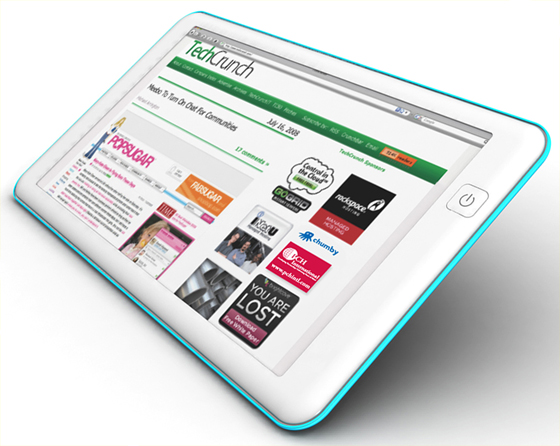
And this is what he says about it.
I’m tired of waiting – I want a dead simple and dirt cheap touch screen web tablet to surf the web. Nothing fancy like the Dell latitude XT, which costs $2,500. Just a Macbook Air-thin touch screen machine that runs Firefox and possibly Skype on top of a Linux kernel. It doesn’t exist today, and as far as we can tell no one is creating one. So let’s design it, build a few and then open source the specs so anyone can create them.
Here’s the basic idea: The machine is as thin as possible, runs low end hardware and has a single button for powering it on and off, headphone jacks, a built in camera for video, low end speakers, and a microphone. It will have Wifi, maybe one USB port, a built in battery, half a Gigabyte of RAM, a 4-Gigabyte solid state hard drive. Data input is primarily through an iPhone-like touch screen keyboard. It runs on linux and Firefox. It would be great to have it be built entirely on open source hardware, but including Skype for VOIP and video calls may be a nice touch, too.
If all you are doing is running Firefox and Skype, you don’t need a lot of hardware horsepower, which will keep the cost way down.
The idea is to turn it on, bypass any desktop interface, and go directly to Firefox running in a modified Kiosk mode that effectively turns the browser into the operating system for the device. Add Gears for offline syncing of Google docs, email, etc., and Skype for communication and you have a machine that will be almost as useful as a desktop but cheaper and more portable than any laptop or tablet PC.
It will also include a custom default home page with large buttons for bookmarked services – news, Meebo/Ebuddy for IM, Google Docs/Zoho for Office, Email, social networks, photo sites, YouTube, etc. Everything that you use every day.
We’re working with a supply chain management company that says the basic machine we’re looking to build can be created for just a few hundred dollars. They need us to write the software modifications to Linux and Firefox (more on that below) and spec the hardware. Then they run with it and can have a few prototypes built within a month…
I don’t have the skills to help him build it. But I’d buy one if it were available. It’s the logical next step on from the NetBook. The experience of the One Laptop Per Child project, however, suggests that designing and building hardware is much more expensive and difficult than people think. I hope I’m wrong.