
If you came on US Patent #7508978 you might stifle a yawn. Certainly you’d never suspect that it might be a design for radically changing our communications environment. Here’s what the Abstract says:
Detection of grooves in scanned images
A system and method locate a central groove in a document such as a book, magazine, or catalog. In one implementation, scores are generated for points in a three-dimensional image that defines a surface of the document. The scores quantify a likelihood that a particular point is in the groove. The groove is then detected based on the scores. For example, lines may be fitted through the points and a value calculated for the lines based on the scores. The line corresponding to the highest calculated value may be selected as the line that defines the groove.
Eh? And yet it turns out that this is the basis for Google’s amazingly efficient book-scanning technology.
In a lovely blog post, Maureen Clements explains how:
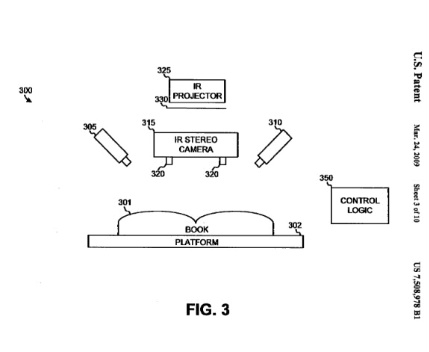
Turns out, Google created some seriously nifty infrared camera technology that detects the three-dimensional shape and angle of book pages when the book is placed in the scanner. This information is transmitted to the OCR software, which adjusts for the distortions and allows the OCR software to read text more accurately. No more broken bindings, no more inefficient glass plates. Google has finally figured out a way to digitize books en masse. For all those who’ve pondered “How’d They Do That?” you finally have an answer.
LATER: How the Internet Archive scans books. As you can see from the movie, it’s pretty labour-intensive, despite the robotics.