
Just discovered (via the Gmail Blog) that if you have keyboard shortcuts enabled (and Gmail.com registered as an exception to the ‘block pop-up windows’ preference) then hitting ‘g’ followed by ‘w’ opens a Google doc. Very useful.
Category Archives: Google
Wapping comes to Wall Street
This morning’s Observer column.
You might think this is all a storm in an online teacup, but in fact it's a revealing case study of how our media ecosystem has changed. What happened is that reporters on a major newspaper got something wrong. Nothing unusual about that – and the concept of "network neutrality" is a slippery one if you're not a geek or a communications regulator. But within minutes of the article's publication, it was being picked up and critically dissected by bloggers all over the world. And much of the dissection was done soberly and intelligently, with commentators painstakingly explaining why Google's move into content-caching did not automatically signal a shift in the company's attitude to network neutrality. Lessig was able instantly to rebut the views attributed to him in the article.
Watching the discussion unfold online was like eavesdropping on a civilised and enlightening conversation. Browsing through it I thought: this is what the internet is like at its best – a powerful extension of what Jürgen Habermas once called "the public sphere".
And the Journal’s response? A snide little “roundup” on its website about critical responses to the article which – it observed – “has certainly gotten a rise out of the blogosphere”. Instead of an apology for a seriously flawed piece of journalism, it produced only a celebration of the outrage its errors had generated. Verily, the Sun has come to Wall Street.
Because my Observer column is limited to about 800 words, there’s a lot more I’d like to have said about this episode. It would have been nice, for example, to have been able to point to some of the more illuminating commentaries on the WSJ story. For example:
I could go on, but you will get the point. This was about as far as you can get from the LiveJournal-OMG-my-cat-has-just-been-sick media stereotyping of blogging. It was an illustration of something that has always been true — that the world is full of clever, thoughtful, well-informed people. What has changed is that we now have a medium in which they can talk to one another — and to newspaper reporters, of only the latter are prepared to participate in the conversation.
I’m searching for metaphors to capture what has happened. One image that comes to mind is that of a vast auditorium or sports arena which is packed to the rafters. In the centre is a stage with a very powerful public address system capable of generating tremendous amplification. Only a few people are allowed onto the stage to speak. When they do, everyone in the stadium can hear them. But they can’t hear the audience; or if they can it’s only as an undifferentiated roar. The performers cannot hear any individual voice.
That’s how it was when newspapers and broadcasters were in their prime. As someone who was first invited onto the stage in 1987 (and has been performing on it continuously ever since), I always felt that it was a privileged position, which carried with it commensurate responsibilities. No doubt many other journalists and columnists felt like that too. But as a group we took our privileged position for granted, and most of us didn’t notice that our technological advantage — the amplification provided by the mass-media publication machine — was eroding. Nor did many journalists notice that network technology — the ‘generative Internet’ in Jonathan Zittrain’s phrase — was busily providing members of the audience with their own global publishing machine. So suddenly we find ourselves in an arena where our amplifiers are losing power, and individual members of the audience can not only talk to one another, they can shout back at us.
But actually, most of the time they don’t want to shout. They want to talk. They think we’re wrong about something that they know about. Or they feel we haven’t done a subject justice, or maybe have missed a trick or even the point. The challenge for mainstream journalism now is whether its practitioners want to participate in the conversation that’s now possible. My complaint about the WSJ’s reaction to the blogosphere’s reaction is that it evinced a refusal to participate. The errors made by its reporters were serious but for the most part understandable; journalism is the rushed first draft of history and we all make mistakes. The tragedy was that the Journal saw the blogosphere’s criticism as a problem, when it fact it was an opportunity.
Google’s Gatekeepers
Sobering piece by Jay Jeffrey Rosen exploring the critical role that Google’s corporate gatekeepers play in deciding what can and cannot be shown to audiences.
“Right now, we’re trusting Google because it’s good, but of course, we run the risk that the day will come when Google goes bad,” [Timothy] Wu told me. In his view, that day might come when Google allowed its automated Web crawlers, or search bots, to be used for law-enforcement and national-security purposes. “Under pressure to fight terrorism or to pacify repressive governments, Google could track everything we’ve searched for, everything we’re writing on gmail, everything we’re writing on Google docs, to figure out who we are and what we do,” he said. “It would make the Internet a much scarier place for free expression.” The question of free speech online isn’t just about what a company like Google lets us read or see; it’s also about what it does with what we write, search and view.
Source: NYTimes.com.
Ed Felten adds this:
Rosen worries that too much power to decide what can be seen is being concentrated in the hands of one company. He acknowledges that Google has behaved reasonably so far, but he worries about what might happen in the future.
I understand his point, but it’s hard to see an alternative that would be better in practice. If Google, as the owner of YouTube, is not going to have this power, then the power will have to be given to somebody else. Any nominations? I don’t have any.
What we’re left with, then, is Google making the decisions. But this doesn’t mean all of us are out in the cold, without influence. As consumers of Google’s services, we have a certain amount of leverage. And this is not just hypothetical — Google’s “don’t be evil” reputation contributes greatly to the value of its brand. The moment people think Google is misbehaving is the moment they’ll consider taking their business elsewhere.
Can Google Flu Trends Be Manipulated?
Interesting contribution to the discussion by Ed Felten.
My concern today is whether Flu Trends can be manipulated. The system makes inferences from how people search, but people can change their search behavior. What if a person or a small group set out to convince Flu Trends that there was a flu outbreak this week?
An obvious approach would be for the conspirators to do lots of searches for likely flu-related terms, to inflate the count of flu-related searches. If all the searches came from a few computers, Flu Trends could presumably detect the anomalous pattern and the algorithm could reduce the influence of these few computers. Perhaps this is already being done; but I don’t think the research paper mentions it.
A more effective approach to spoofing Flu Trends would be to use a botnet — a large collection of hijacked computers — to send flu-related searches to Google from a larger number of computers. If the added searches were diffuse and well-randomized, they would be very hard to distinguish from legitimate searches, and the Flu Trends would probably be fooled.
This possibility is not discussed in the Flu Trends research paper. The paper conspicuously fails to identify any of the search terms that the system is looking for. Normally a paper would list the terms, or at least give examples, but none of the terms appear in the paper, and the Flu Trends web site gives only “flu” as an example search term. They might be withholding the search terms to make manipulation harder, but more likely they’re withholding the search terms for business reasons, perhaps because the terms have value in placing or selling ads.
LIFE Photo Archive available on Google Image Search
Wow! This is big news.
The Zapruder film of the Kennedy assassination; The Mansell Collection from London; Dahlstrom glass plates of New York and environs from the 1880s; and the entire works left to the collection from LIFE photographers Alfred Eisenstaedt, Gjon Mili, and Nina Leen. These are just some of the things you’ll see in Google Image Search today.
We’re excited to announce the availability of never-before-seen images from the LIFE photo archive. This effort to bring offline images online was inspired by our mission to organize all the world’s information and make it universally accessible and useful. This collection of newly-digitized images includes photos and etchings produced and owned by LIFE dating all the way back to the 1750s.
Only a very small percentage of these images have ever been published. The rest have been sitting in dusty archives in the form of negatives, slides, glass plates, etchings, and prints. We’re digitizing them so that everyone can easily experience these fascinating moments in time. Today about 20 percent of the collection is online; during the next few months, we will be adding the entire LIFE archive — about 10 million photos.
Thanks to Tony Hirst for spotting it first.
Google’s predictive power (contd.)
The story continues. Here’s Bill Thompson’s distinctive take on it.
As we have seen with flu trends, sometimes the “interesting” knowledge that can be extracted is well-concealed until comparisons can be made with other sources, as it was the correlation between some search terms and the real-world data that mattered.
Of course Google has not revealed which search terms it analysed because doing so would undermine the model’s effectiveness.
Unfortunately it is being equally reticent about how it has ensured that the data its uses is properly anonymised so that users cannot be identified on the basis of their queries.
A letter from the Electronic Privacy Information Center (EPIC) and Patient Privacy Rights to Google boss Eric Schmidt has not been answered, leaving those concerned with online privacy uncertain over the broader implications of the project.
But as Cade Metz points out in an insightful article in The Register, we may all be happy to know that a ‘flu outbreak is coming, but what happens when the disease involved is more life-threatening and the government asks Google for the names and IP addresses of anyone whose search terms indicate that they are infected?
It’s not that I don’t trust Google. I don’t trust any company, government department or individual without a good reason to do so.
In the case of search engines that claim to protect my privacy I want to know just how they do it and will not accept vague reassurances.
Google, the Collective Unconscious and PEAR
Hmmm… this Google Trends idea gets more intriguing by the minute. Rex Hughes read my comumn and pointed me at the Princeton Engineering Anomalies Research Program, which I guess was funded by You Know Who at the Pentagon. The project has closed, but here’s the blurb:
The Princeton Engineering Anomalies Research (PEAR) program, which flourished for nearly three decades under the aegis of Princeton University’s School of Engineering and Applied Science, has completed its experimental agenda of studying the interaction of human consciousness with sensitive physical devices, systems, and processes, and developing complementary theoretical models to enable better understanding of the role of consciousness in the establishment of physical reality. It has now incorporated its present and future operations into the broader venue of the International Consciousness Research Laboratories (ICRL), a 501(c)(3) organization chartered in the State of New Jersey. In this new locus and era, PEAR plans to expand its archiving, outreach, education, and entrepreneurial activities into broader technical and cultural context, maintaining its heritage of commitment to intellectual rigor and integrity, pragmatic and beneficial relevance of its techniques and insights, and sophistication of its spiritual implications.
It lives on here.
Google Search Data Trends
As usual, my colleague Tony Hirst has taken an idea and explored it in more depth. As we get further down this track we will, of course, come up against our old friend, mistaking-correlation-for-causation syndrome. But, hey, that some way away yet!
Skype just got Googled
The toughest question a venture capitalist can ask a company seeking finance is “what happens if Google decides to move in on your turf?” (Thus far, nobody has come up with a good answer to that question, though we live in hope.) Skype, the VoIP company bought by eBay for an unconscionable sum some years ago, has just encountered that moment. Late yesterday I noticed a little red notice on the top of my Gmail screen saying “New Video Chat!” — Google chat had just been upgraded to handle video. And so, after a quick install and restart of the browser, it has. The guys who unloaded Skype onto eBay and pocketed the loot must be grinning from ear to ear today.
Google as a predictor
Following on from this post and today’s Observer column, I’ve had some feedback asking how one might go about using Google queries as forward indicators of economic developments. The answer is that I don’t know, but it probably hinges on finding the right search queries to map. Here are some experiments I’ve done.
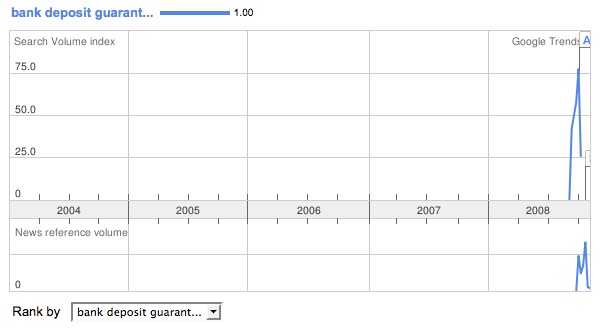
This suggests that people weren’t really concerned about bank deposit guarantees until August 2008. I don’t believe this, so perhaps this is the wrong search term to be tracking.
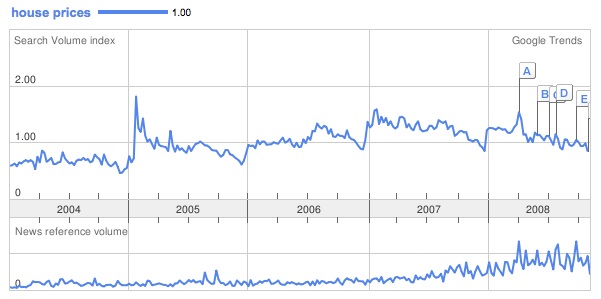
This suggests that the peak of interest in house prices occurred in 2005 and is now in gentle decline. This might indicate that this search term is a token for general curiosity (“wonder why our house is worth at the moment?”) rather than alarm. It’s interesting to compare this with the chart for ‘negative equity’ below.
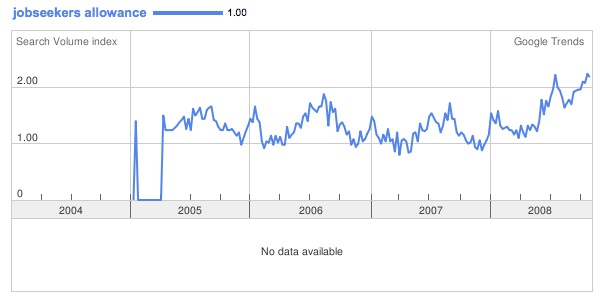
This has a regular annual cycle but is now clearly on the rise. Again, it’s not clear that it has much predictive power.
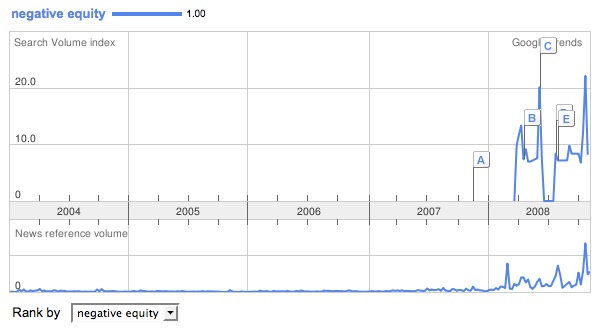
Speaks for itself, I think.
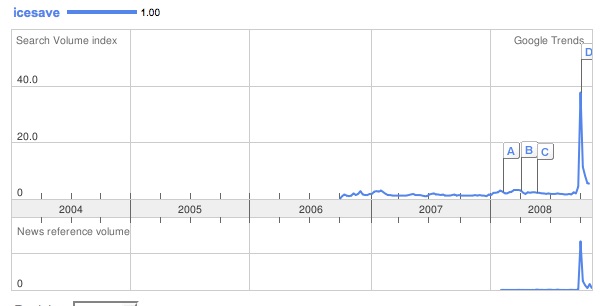
Ditto.
As I say, the trick would be to identify search terms which would give an indication of what people know or suspect about their organisational future.
There’s nothing terribly systematic about this — I was just trying to think of search terms that might reveals what people were thinking as they realise that they face an uncertain future.
Tony Hirst, who is the nearest thing to a wizard with Google data that I know, has some interesting things to say about the topic. He’s also knowledgeable about the limitations of the Google data.